最近有朋友私信询问PoC挖矿的问题,使用PoC算法的两种币BitcoinHD(BHD)和BurstCoin(BURST)也铺天盖地的在各种群中传播,大有取代PoW的架势。
相比PoW,PoC可以大大节约能源和计算资源,确实有可能成为未来的一种趋势。
下面就让我们来看看,这个PoC到底是怎么回事儿。
什么是容量证明(PoC)
PoC是Proof of Capacity的缩写,翻译成汉语就是容量证明。
顾名思义,就是通过存储容量的多少来决定区块生成权的算法。
PoC并不是一个刚出现的概念,第一个应用PoC算法的加密货币是BurstCoin。
BurstCoin早在2014年8月便发布了,并一直存活至今。
最早的PoC算法就是BurstCoin提出并实现的。
只是在2014年的熊市中,没有得到足够的关注。
2017年的狂热中,又被一堆矿机厂商鼓吹的PoW所掩盖,一直默默无闻。
PoC准确的说应该是一类算法的统称,就像PoW算法有X16R、X11、Ethash等一样。
目前出现的PoC算法并不多,只有两种加密货币在使用,并只有一种算法实现,就是BurstCoin的PoC算法。
容量证明的优点
传统的PoW算法通过把区块的生成与芯片需要消耗电力这一物理规律绑定,无人可以逾越这个规律,成功的解决了区块链的安全问题。
但是PoW也存在诸多缺点:
- 消耗大量能源
- 对挖矿设备有较高要求。从最开始的CPU、GPU,慢慢演变到ASIC,需要专门生产和购买
以上的缺点不可避免的造成了PoW挖矿门槛逐渐提高。
拥有廉价电力的矿场和矿机厂商逐渐垄断了挖矿市场,矿霸开始出现,并造成了诸多问题。
矿难时,大量ASIC设备因为只能挖矿不能做其他用途而被废弃,浪费资源,污染环境。
BurstCoin的设计者把去中心化作为第一目标,力求人人可以参与,最终,他们成功地提出了一种PoC算法。这个BurstCoin还真是低调,都没给自己实现的PoC算法起个名字。
为了不造成混淆,我们把BurstCoin的PoC实现称为BurstCoin-PoC算法。
BurstCoin-PoC算法有如下特点:
- 存储硬化,强制占满所有用来挖矿的存储空间。
这意味着,提高挖矿效率最有效也是唯一可行的方法是增加用于挖矿的存储容量。
- I/O不敏感,对存储设备的读写速度要求不高。
这意味着,并不需要RAID、SSD、甚至是内存等较为昂贵和特殊的存储设备,挖矿的门槛大大降低。
- 网络带宽不敏感,挖矿的搜索过程本身是离线的,仅接收、广播交易和区块时,才需要网络。
这意味着,不需要大量使用网络带宽这种高度中心化的资源。
- 计算资源不敏感,一旦挖矿所需的数据生成完毕,实际挖矿过程中,几乎不需要计算资源参与。
这意味着,挖矿不再需要强大的CPU、GPU,不再需要消耗大量能源。
结合这些特点,每台计算机都有的机械硬盘成了挖矿的最佳选择,这几乎是人人都可以达到的,大大降低了挖矿的门槛,甚至,部分大容量的手机、平板电脑等设备也可以参与挖矿,避免造成挖矿中心化。挖矿设备为硬盘,即使遭遇矿难,也不再会像ASIC一样,不能做任何其他用途,只能变成电子垃圾,污染环境,浪费资源。硬盘的能耗远低于其他计算型硬件,有利于节约能源。
PoC算法的核心是将区块的生成与存储设备的存储密度不能无限提高这一物理规律相绑定,从而限制区块的生成,保障区块链的安全,最终使整个区块链达成共识。
BurstCoin-PoC算法的原理
在计算机科学中,一些经常需要用到的数据和中间结果,会被存下来,这就是缓存。
缓存是一种非常常见的做法,让我们举一个例子,假如我们要做如下的计算:
- 45 x 55
- 45 x 55 + 934
- 45 x 55 + 723
- 45 x 55 + 98
如果所有计算都正常执行的话,需要4次乘法和3次加法。
聪明的你一定发现了,45 x 55出现了四次,干嘛每次都要重新算,只算一次,然后把结果记录下来,下次再遇到,就直接用结果,不需要再次计算。
于是,完成同样的工作,我们只需要1次乘法和3次加法。
不过,节约计算量也不是没代价的,代价就是我们需要一块儿空间,来存储这个中间结果。
这种做法就叫空间换时间,越是复杂的计算,缓存就越能提高性能。
PoW算法为了保证公平性,对每个区块进行竞争时,求解的谜题都是全新的,完全没有任何可以复用的中间结果。
BurstCoin-PoC同样设计了一种很消耗计算资源的算法,但与PoW不同的是,这个计算过程中,最复杂的部分是可以缓存的,这就造成了消耗存储空间进行缓存的做法可以获得巨大的优势。
正如我们之前提到的,越是复杂的计算,消耗存储空间进行缓存的做法就可以获得越大的优势,也就更可以保证矿工选择更大的存储空间而不是更强的计算能力进行竞争。
但是,计算复杂度是不能无限提高的,因为,非矿工的用户在校验区块的PoC结果时,是需要针对这个结果重新进行一遍计算的,我们不能要求一个不挖矿的用户也配备大量存储资源进行缓存。
过高的计算复杂度会造成普通用户校验区块速度很慢。因此,计算复杂度的高低需要一定的均衡,既不能太复杂造成校验困难,也不能太简单造成缓存优势不足,从而退化成PoW。
用足够高的计算复杂度,人为造成空间换时间的巨大优势,这就是BurstCoin-PoC算法的原理。
BurstCoin-PoC算法的实现
BurstCoin-PoC算法的核心是一个哈希函数:Shabal。
美国国家标准与技术研究院(NIST)在2007年举办了一个竞赛,为制定下一代哈希函数标准征集方案,Shabal就是其中的候选方案。这个方案通过了第一轮的筛选,很遗憾,它没有通过第二轮,无缘决赛。不过,Shabal依然是一个很好的哈希算法,至今也没有发现明显的安全弱点。
实际上,这次竞赛中的很多算法,虽然最终没有获胜,却因为各自优秀的特性而被加密货币选中,PoW算法X11中的11种哈希算法,很多就是出自这次竞赛的候选方案。
下面就让我们看看BurstCoin-PoC算法具体是怎么实现的。
BurstCoin-PoC需要生成大量的缓存数据,这些缓存被称为Plot文件。
第一步:选择一个8字节的随机数Nonce,加上你的Account ID一起进行Shabal256计算,得到一个Hash结果。这个Account ID是从你的私钥推倒出来的,可以用来标识你的身份,之所以要在计算中加上Account ID,是为了避免几个人共用同一套缓存数据来作弊,也增加了搜索空间的范围。哈希结果被称为Hash #8191,这不是错误,下面会解释为什么这么命名。
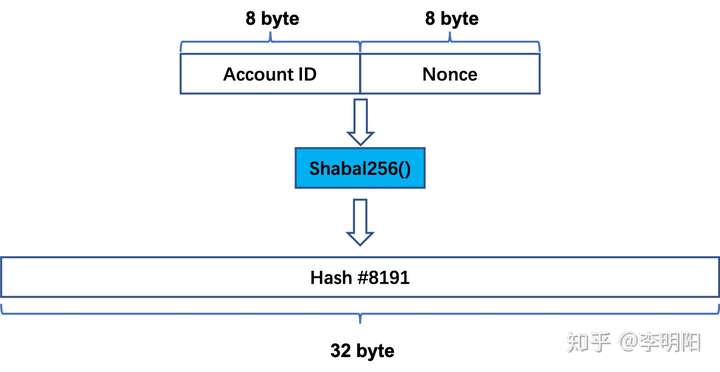
然后,把第一步得到的Hash #8191添加到Account ID和Nonce前面,再进行一次Shabal256计算,得到Hash #8190。
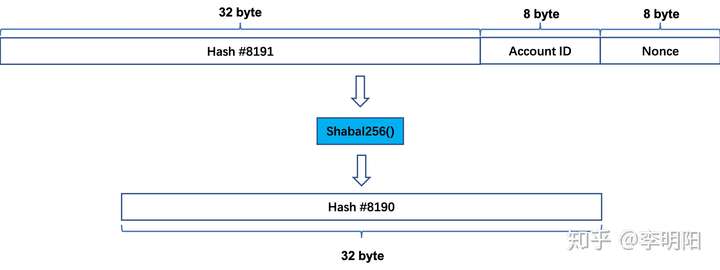
以后的计算中,每次都把得到的Hash值添加到数据的前面,当数据的长度超过4096字节后,每次只取最近的4096字节数据进行哈希。
比如计算Hash #7000的时候,其实只会取Hash #7001-7128这128个哈希值进行计算。
因为每个哈希值的长度是32字节,128个正好是4096字节。
当完成了8192次循环后,你会得到8192个哈希值,用来计算哈希值的数据也会变成这样:
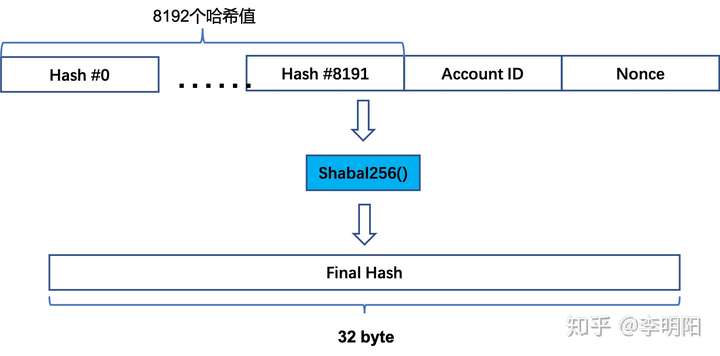
你需要对所有这些数据再进行一次Shabal256计算,得到一个Final Hash。
最后,把之前的8192个哈希值逐个和Final Hash进行异或运算,得到的8192个异或后的哈希值保存下来,这些数据就是未来挖矿时需要搜索的范围。
这8192个哈希值会两两一组,称为一个Scoop,一个Scoop是挖矿使用的最小数据单位,一个Scoop是64字节。

现在可以解答前面的问题了,其实Hash的编号是倒着来的,这就是为什么第一次Hash运算的结果叫Hash #8191而不是Hash #0了。
对每个矿工来说,Account ID是固定的,上面生成的8192个Hash值其实只和Nonce有关,Nonce是8字节的,取值范围在0-18446744073709551615,这是个非常大的数字。
一个Nonce对应的数据量是32字节*8192 = 256KB。
如果想存储所有Nonce对应的数据,需要256KB x 18446744073709551615 = 4096ZB的空间,而人类目前所有数据加起来,据说不超过40ZB,事实上想预先存完所有Nonce的数据是不可能的。
矿工只会尽可能多地缓存Nonce和对应的4096个Scoop来提高自己找到解的概率。
存储的优化
记得之前我们说过的吗?
BurstCoin-PoC还有一个设计要求,那就是对I/O要求要尽可能低。
降低I/O要求有两种方法:
- 减少要读取的数据量
- 优化数据排布,减少I/O次数
BurstCoin-PoC算法采用了第一种方法。
事实上,BurstCoin-PoC进行搜索的时候,只会搜索所某个固定编号的Scoop。
假设某个矿工缓存了如下的数据:
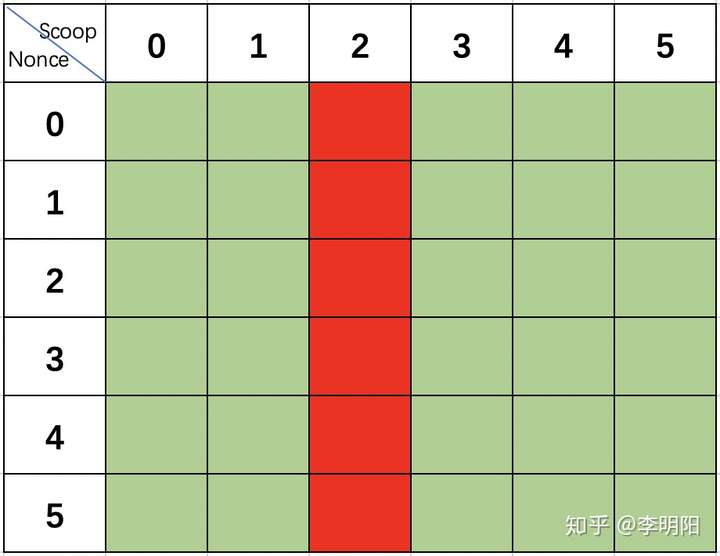
这张表格并不完整,只是为了说明问题,省略了很多Scoop,也只画出了5个Nonce,真实的矿工会缓存比这多得多的数据。
某个区块挖掘时,选择了Scoop2进行扫描,于是,矿工只需要扫描4096个Scoop中的一个即可,大大减少了需要读取的数据量。
不要担心矿工会删除其他的Scoop,因为不同区块会近乎随机的选择需要使用的Scoop,如果不存储某个Scoop,就意味着他将不能参与需要这个Scoop的区块的挖矿,成比例地降低了挖矿效率。如果他存储的Nonce不够多,那么他能搜索的范围就会减小,也会成比例地影响他的挖矿效率。
我们来算一下,即使矿工使用目前单盘容量最大的硬盘,比如希捷酷狼14T。

14T硬盘实际可用12.7T左右,即使缓存满了数据,也只需要扫描12.7T x 1 / 4096=3100.5859MB的数据。
BurstCoin的区块时间是4分钟,只要硬盘可以在这4分钟内完成扫描即可。
3100.5859MB / 240s = 12.91910792MB/s,只要硬盘的读写速度超过这个值即可,一般机械硬盘的读写速度都超过150MB/s。
BurstCoin-PoC帮矿工减少了每个区块需要扫描的数据量,矿工们也很聪明,他们使用了第二种方法,减少I/O次数,进一步优化。
想象下,你去超市买东西,可乐和啤酒都放在同一个架子上,你只要跑一趟就都拿到了。
相反,尿布和啤酒可能离得非常远,你就要跑两趟了。
超市发现了很多人同时买了啤酒和尿布,于是把他们放在了同一个货架上,大家又可以只跑一次就拿到两件东西了,这就是超市对商品排布的优化。
与超市的例子非常类似,对机械硬盘来说,数据是存储在盘片上的不同位置的,如果数据存储的位置离得很近,就可以在一次I/O中完成读取。
让我们看个例子吧:
Plot文件刚刚生成的时候,是按Nonce存储的,相同Nonce的不同编号的Scoop存储在一起。
相同颜色代表存储在靠近的位置,不同颜色代表存储的位置相隔较远。
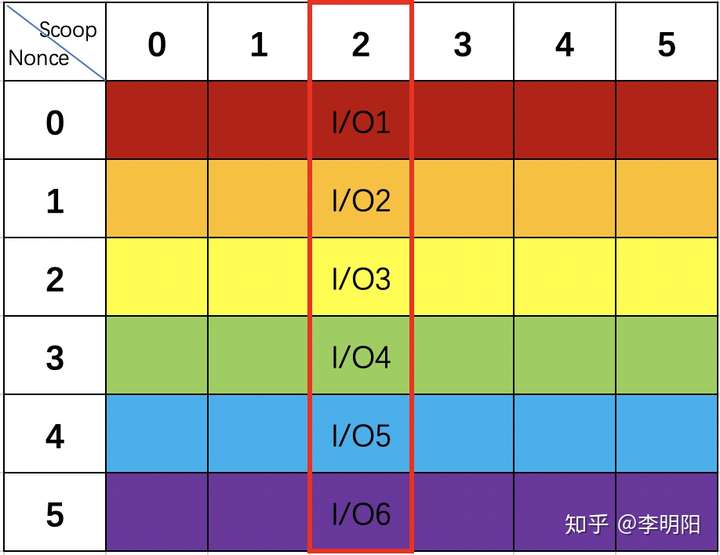
但是,挖矿时是按Scoop来进行扫描的,如果这样排列,我们扫描0-5六个Nonce的Scoop2需要6个I/O。
这会大大影响扫描的效率,也会影响硬盘的寿命。
于是,聪明的矿工会在Plot文件生成后,对数据进行一个重排,就像下面这样:
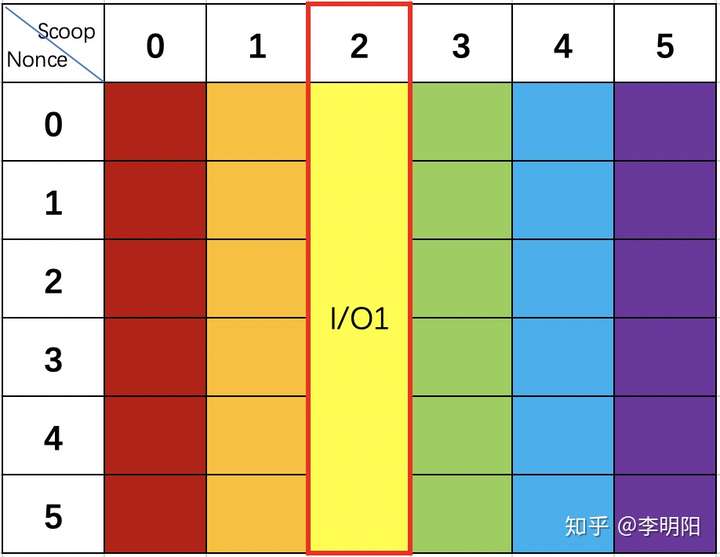
把Nonce拆散,相同的Scoop放在一起,这样的话,访问一个Scoop就只需要一次I/O啦,是不是很机智?
事实上,在这两种优化的作用下,绝大多数硬盘只需要不到30秒就可以扫描完所有的数据,几乎不会对计算机的正常使用造成影响,真正做到挖矿和正常使用两不耽误。你可以一边玩着游戏,一边挖着矿,美美的。




